CPU 스케줄링 & 선점형, 비선점형 스케줄링 [ 운영체제(OS) 면접 질문 3]
스케줄(Schedule)
우리는 시간에 따라 세운 계획을 표현할 때 "일정, 계획, 시간표, 스케줄" 등등의 단어를 사용한다.
CPU 스케줄링은 위의 정의를 그대로 사용한다. "시간"이라는 자원 아래에서 CPU가 처리할 작업들의 일정과 계획을 세우는 것이다.
어떤 프로세스를 실행시켜야 하는지는 CPU 스케줄러에 달려있다.
어떤 목적과 어떤 정책을 중점으로 CPU 스케줄러를 운영해야 하는지를 살펴본다.
CPU 스케줄링
작업(스레드)의 형편성과 효율성을 결정하는 중요한 일을 한다. 어떤 작업에 CPU를 배정할지 결정하는 것이다.
CPU 스케줄러는 프로세스의 "생성"부터 "종료"까지 모든 상태 변화를 "조정"한다.
CPU 스케줄링의 목적
1. 공평성
- 모든 프로세스가 자원을 공평하게 배정받아야 한다. 자원 배정 과정에서 배제되어서는 안 된다.
[ 해당 목적은 CPU 스케줄링 알고리즘에서 중요하게 다루어진다. ]
2. 효율성 [ 상당히 중요 ]
- 시스템은 "유휴 시간(idle)"이 없도록 사용되어야 한다.
- 유휴 자원을 필요로 하는 프로세스에 "우선권"을 주어야 한다.
시스템 입장에서 유휴 자원은 CPU이다.
3. 안정성
- 시스템을 강제로 점유하거나, 파괴하려는 프로세스로부터 자원을 보호해야 한다.
4. 반응 시간 보장
- 적절한 시간 안에 프로세스의 요구에 반응해야 한다.
5. 무한 연기 방지.
- 특정 프로세스의 작업이 무한하게 연기되어서는 안 된다.
프로세스의 우선순위
CPU 스케줄러에서 준비 상태에 있는 프로세스에서 자원을 할당할 프로세스를 뽑기 위해서 사용하는 값이 "우선순위"이다. 한정된 자원 아래에서 "우선순위"는 상당히 중요한 값이다.
프로세스는 크게 커널과 사용자 프로세스로 나뉘는데, 커널 프로세스가 사용자 프로세스보다 우선순위가 높다.
우선순위가 높다는 것은 더 빨리 그리고 더 자주 실행됨을 의미한다.
운영체제는 CPU 스케줄링 알고리즘에 따라서 준비 상태에 있는 Queue 프로세스 중 하나를 선택해서 실행한다.
우선순위는 프로세스가 가지고 있는 PCB 블록에 저장되어 있다.
프로세스의 실행 : CPU와 IO 대기
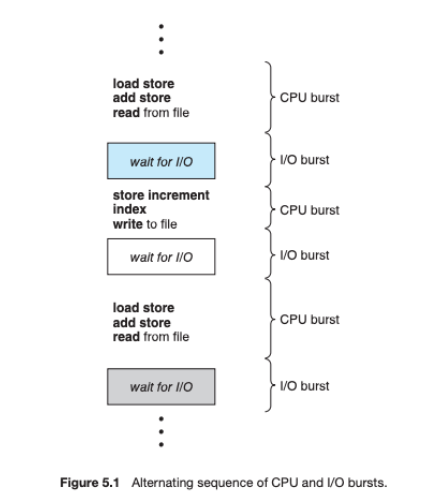
대부분의 프로세스는 IO 작업과 CPU 작업을 같이 진행한다. CPU 실행과 CPU 결괏값을 IO로 반영하는 시간으로 프로세스의 생애주기가 구성되는 것이다.
문제는 "시간"이라는 자원에서 CPU보다 IO의 시간이 더 오래 걸린다는 것이다. CPU 작업의 결과를 IO로 반영하기 위해 CPU가 대기하는 시간은 "유휴 시간"으로 남게 되고 위의 "효율성" 목적에 반하게 된다.
그래서 IO 작업을 대기하는 프로세스를 "대기"상태로 넘기고 해당 유휴시간 동안 다른 프로세스를 "실행" 상태로 배치시켜서 시스템의 자원의 효율성을 높이는 것이다.
준비 큐에는 "CPU"를 필요로 하는 프로세스들이 존재하고 "실행" 상태에서는 CPU 작업 후 IO 대기 시간이 존재하는 프로세스들이 존재하기 때문에 CPU 스케줄링이 상당히 중요한 역할을 하게 되는 것이다.

dispatch의 4가지 상황
IO 대기 시간을 효율적으로 처리하기 위해 wating 상태로 프로세스를 옮긴다.
IO 대기 시간 동안 CPU의 유휴시간을 스케줄러는 우선순위를 살펴보고 적절한 프로세스를 뽑아 running 상태로 옮겨야 한다.
dispatch는 다음의 상황에서 발생할 수 있다
1. 실행 중인 프로세스가 대기 상태로 전환되는 경우 [ CPU Bound -> IO Bound ]
2. 실행 중인 프로세스가 "인터럽트"를 받고 준비 상태로 넘어가는 경우.
현재 작업을 "준비"로 보내고 준비 상태의 프로세스를 "실행" 상태로 전환한다.
3. 한 프로세스가 대기 상태에서 준비 완료 상태로 전환된 경우 : wating -> ready
준비 완료로 돌아온 프로세스의 우선순위가 높다면 바로 running으로 넘어가야 할 것이다
4. 작업 프로세스가 끝나서 CPU가 유휴 상태로 넘어간 경우.
1번과 4번은 작업 중인 프로세스가 스스로 CPU 자원을 내려 놓기 때문에 비선점형 방식으로 본다.
2번과 3번의 경우 우선순위 혹은 인터럽트(스케줄링 정책)에 따라 강제적으로 CPU 자원을 뺏기 때문에 선점형 방식으로 본다.
선점형의 경우 다중 프로세스가 공유하는 데이터가 문제가 될 수 있어 "데이터 동기화"를 안정적으로 관리해야 한다. [ 이는 추후에 주제에서 살펴본다. ]
[ 입출력 집중 프로세스의 경우 우선순위를 높이면 대기 상태로 바로 넘어가기에 시스템의 효율성이 향상될 수 있다. ]
Dispatcher : ready -> running으로 프로세스를 넘기는 모듈
CPU 코어의 제어를 CPU 스케줄러가 선택한 프로세스에 주는 "모듈"이다. 다음의 일을 처리한다.
1. 현재 작업중인 프로세스의 컨텍스트를 해당 프로세스가 지닌 PCB에 저장한다.
2. 준비 큐에서 선택한 프로세스의 PCB 컨텍스트를 가져온다.
3. 커널 모드에서 사용자 모드로 전환한다.
4. 프로그램에 CPU 제어권을 넘기고 사용자 프로그램을 실행한다.
[ 컨텍스트란 처리해야 할 작업(스레드)와 관련된 정보들이다. ]
선점형 스케줄링과 비선점형 스케줄링
앞에서 dispatch의 과정을 살펴봤다.
선점형으로 처리되어야 하는 과정이 있고, 비선점형으로 처리되어야 하는 과정이 있다.
선점형 스케줄링 [ 대부분의 CPU 스케줄링 방식이다. ]
위에서 살펴본 dispatch 과정에서 1-4번을 모두 허용
필요한 경우 운영체제가 CPU의 자원 권한을 뺏어서 더 우선적인 프로세스의 작업으로 교체시킬 수 있는 방식이다.
CPU는 인터럽트를 받으면 현재 실행 중인 작업을 중단하고 커널을 깨워서 인터럽트를 처리해야 한다.
"작업의 교체"에 자율성을 얻으나 문맥 교환의 오버헤드와 데이터 동기화 이슈를 해결해야 한다.
빠른 응답 시간을 요구하는 대화형 시스템과 시분할 시스템에 적합하며 대부분의 저수준 스케줄러가 선점형 스케줄링 방식을 따른다.
비선점형 스케줄링
위에서 살펴본 dispatch 과정에서 1번과 4번의 과정만 허용한다.
프로세스가 CPU를 점유하고 있는 경우 다른 프로세스가 CPU 자원을 빼앗을 수 없다.
해당 프로세스가 자발적으로 대기 상태로 들어가기 전까지는 해당 프로세스가 CPU를 점유하게 된다.
작업 처리가 상당히 단순하여 배치 처리 방식(과거의 OS 스케줄링)에 적합하다.
마무리
CPU 스케줄링과 비선점 그리고 선점형 방식 스케줄링에 대해서 살펴보았다.
CPU 스케줄링 알고리즘과 데이터 동기화 이슈(데드락, 세마포어, 뮤텍스, 모니터) 등등의 배경에 접근한 것이다.
OS에서의 기술 면접 질문은 프로세스와 관련된 질문과 "데이터 동기화"인데 그 배경을 알게 되면 이해에 도움이 될 것이라고 생각한다.
다음으로는 "CPU 스케줄링 알고리즘"과 "데이터 동기화" 파트를 살펴보고자 한다!
잘못된 정보가 있는 경우 지적해주시면 바로 수정하겠습니다.
참고 자료
책
- 쉽게 배우는 운영체제
블로그